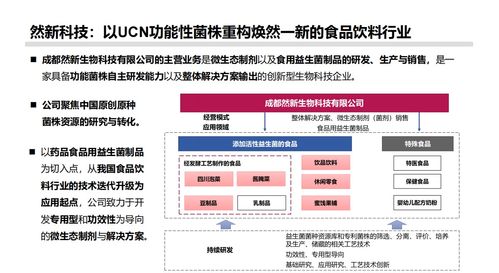
在當今追求高效節(jié)能與可持續(xù)發(fā)展的時代,中廣歐特斯熱泵空調(diào)憑借其創(chuàng)新的技術和服務理念,引領行業(yè)新風向。公司以‘十年質(zhì)保’為基石,結(jié)合新材料技術推廣服務,不僅提升了產(chǎn)品可靠性,更推動了整個產(chǎn)業(yè)鏈的升級。熱泵技術作為清潔能源應用的關鍵一環(huán),中廣歐特斯采用先進的新材料,如高效換熱器和環(huán)保制冷劑,顯著提升了能效比和耐久性,同時通過全方位的技術服務,確保用戶享受到持久穩(wěn)定的冷暖體驗。這一戰(zhàn)略不僅贏得了市場口碑,更彰顯了企業(yè)對社會責任的擔當,為綠色建筑和節(jié)能減排貢獻了力量。未來,中廣歐特斯將繼續(xù)以技術領航,拓展新材料應用,譜寫服務與創(chuàng)新的華彩篇章。
十年質(zhì)保,技術領航 中廣歐特斯熱泵空調(diào)譜寫服務華彩新篇

如若轉(zhuǎn)載,請注明出處:http://www.jzgcc.cn/product/8.html
更新時間:2026-06-19 14:58:11
產(chǎn)品列表
PRODUCT
----------------