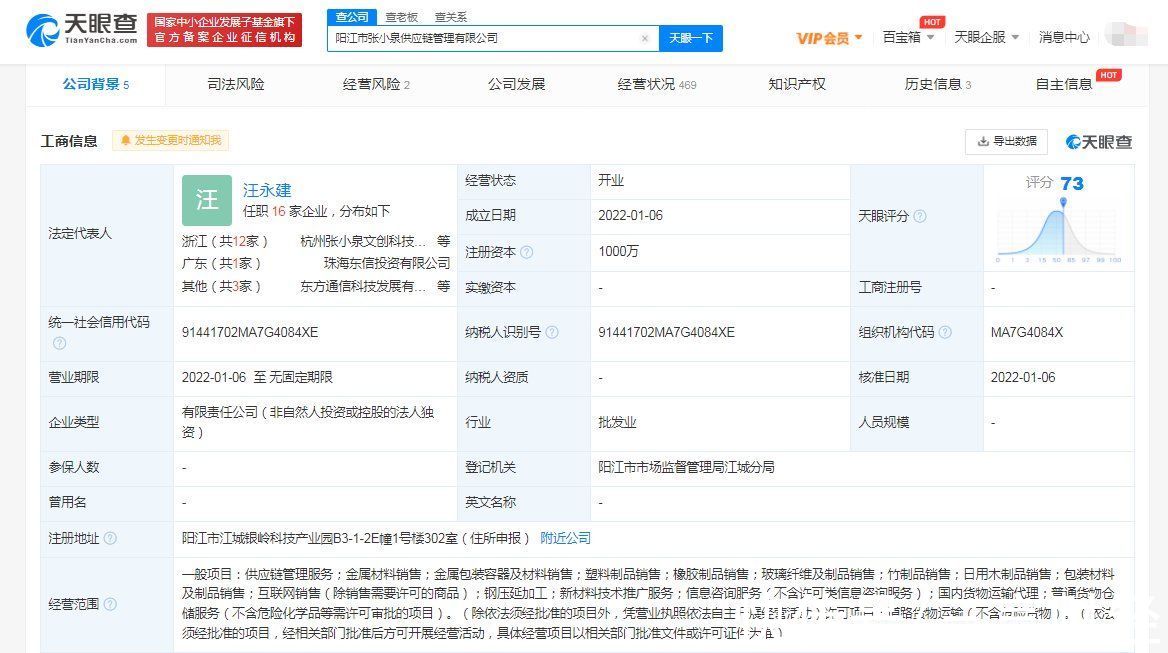
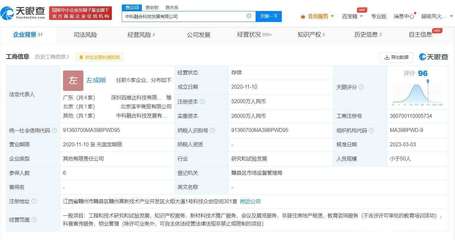
在科技浪潮奔涌向前的2020年,中國合瑞科技以其前瞻性的視野與扎實的創新實力,推出了年度產品畫冊,不僅是對公司技術成果的一次集中展示,更是對“探索科技發展永不止步”這一企業精神的生動詮釋。這份畫冊,如同一扇窗口,向業界與合作伙伴展現了合瑞科技在新材料領域的深耕細作與未來藍圖。
產品畫冊作為企業形象與產品技術的重要載體,合瑞科技的2020年版精心編排,內容翔實。它不僅系統介紹了公司在先進復合材料、高性能聚合物、納米材料及特種功能材料等領域的最新研發成果與成熟產品線,更通過清晰的技術參數、應用案例與視覺效果,直觀呈現了這些材料在航空航天、新能源汽車、高端裝備制造、電子信息及綠色建筑等關鍵行業的解決方案。畫冊的設計兼具專業性與藝術性,體現了科技與美學的融合,讓復雜的材料科學變得可觸、可感、可應用。
而“探索科技發展永不止步”不僅是畫冊的主題,更是合瑞科技深入骨髓的研發理念。公司深知,新材料是高新技術發展的先導和基石,是產業升級換代的核心驅動力。因此,畫冊背后,是持續的研發投入、緊密的產學研合作以及對國際前沿技術的敏銳追蹤。合瑞科技致力于突破材料性能的極限,解決下游產業的應用痛點,以創新材料賦能中國制造向中國智造的轉型升級。
與產品畫冊相輔相成的,是合瑞科技著力打造的“新材料技術推廣服務”。這一服務體系超越了傳統的產品銷售模式,構建了一個全方位、全周期的技術賦能生態。其核心內容包括:
- 定制化解決方案咨詢:基于客戶的具體需求與行業特點,提供從材料選型、工藝設計到性能優化的全程技術咨詢。
- 聯合應用開發與測試:與客戶建立聯合實驗室或開發項目,共同進行新材料應用場景的探索、原型試制與可靠性測試,加速創新落地。
- 技術培訓與研討會:定期舉辦線上線下的技術講座、行業研討會及實操培訓,分享前沿技術動態與應用經驗,提升產業鏈整體的技術水平。
- 售后技術支持與迭代:提供完善的技術支持網絡,確保材料應用的穩定可靠,并根據市場反饋持續進行產品迭代與優化。
通過這種深度捆綁的服務模式,合瑞科技將自身定位為客戶的“戰略合作伙伴”,而非簡單的供應商。技術推廣服務確保了新材料能夠被正確、高效地應用,最大化釋放其性能潛力,幫助客戶提升產品競爭力,共同開拓新市場。
中國合瑞科技將繼續秉持“永不止步”的探索精神,以2020年產品畫冊為新的起點,不斷深化在新材料領域的技術儲備,完善技術推廣服務體系。公司將緊抓新一輪科技革命與產業變革的機遇,推動更多高性能、綠色化、智能化的新材料走向市場,為中國乃至全球的科技進步與產業升級貢獻堅實的“材料力量”。這份畫冊,不僅記錄了過去一年的成就,更吹響了邁向更高峰的前進號角。